
This post is a summary of the project and paper I and my teammate Stijn completed in Spring 2018. We decided to study recurrent neural networks (RNNs), specifically those employing Long Short Term Memory Cells (LSTMs) to produce some surprisingly powerful results. Finally, we applied this onto textual training sets and generated unique word sequences in the style of the training datasets. This was inspired from the 2013 Graves paper “Generating Sequences With Recurrent Neural Networks” (link).
The following sections explain the basics of neural networks, RNNs, and LSTMS, ending with some outputs from our code. Finally, you can read the paper I wrote on the subject, which goes into a bit more depth on the subject.
Neural Networks
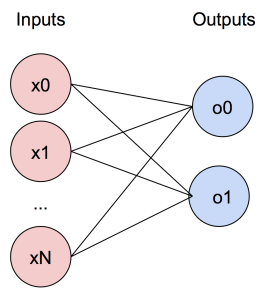
Neural networks are typically composed of networks such as the simple MISO (multiple input single output) perceptron shown below; multiple weights are applied to inputs, summed, and then put through a nonlinear filter. By increasing the complexity of this by first including multiple outputs:
By increasing the complexity of this by first including multiple outputs:
And then by sequentially applying these MIMO (multiple input, multiple output) perceptrons, we get the basic multi-layer, or “deep”, neural network:
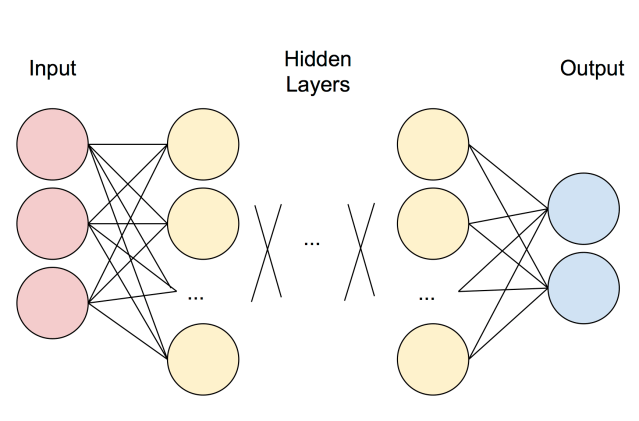
In order to train neural networks to give the desired output, backpropagation is used by first defining a loss function , and then using gradient descent to attempt to minimize this loss function.
Recurrent Neural Networks
RNNs are an expansion upon the neural networks shown before, except are designed to work on sequential datasets (such as audio, text, or visual information). These have a separate neural network for each time step, which both receives and outputs a “state” variable from the previous step, and to the next step.
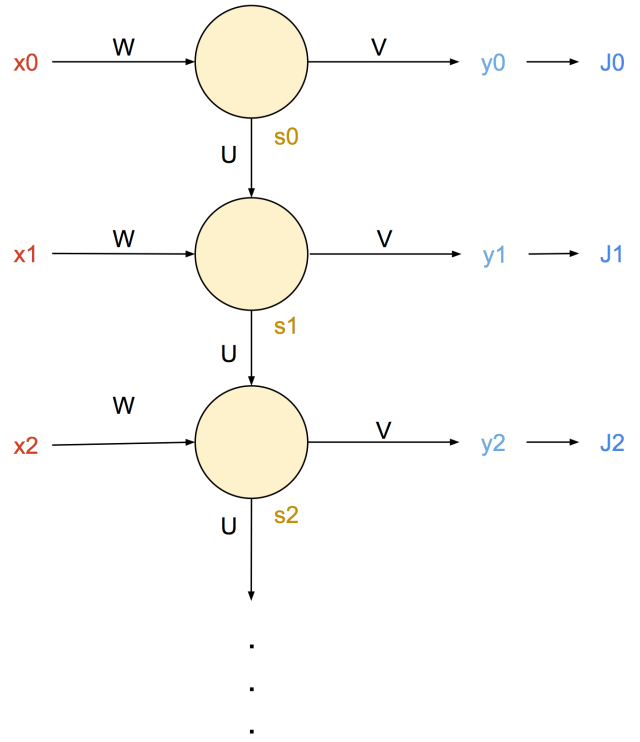
In the following diagram, the inputs are labeled x0 through xn, and the states are s0 through sn. These are applied with weights W and U, respectively. It is important to note, that each yellow circle represents a full neural network (unlike the previous diagrams, which only represented inputs and outputs). These are also trained with a loss function (calculated at each timestep), on which backpropagation can be applied via gradient descent. Here, the weights of the output are V, which result y0 through yn, which produce an amount of error (or loss) of Jn.
These are also trained with a loss function (calculated at each timestep), on which backpropagation can be applied via gradient descent. Here, the weights of the output are V, which result y0 through yn, which produce an amount of error (or loss) of Jn.
RNNs can also be represented more compactly by “folding” them; the previous diagrams were of “unfolded” RNNs though each timestep. The next figure shows how the state is fed back into itself iteratively.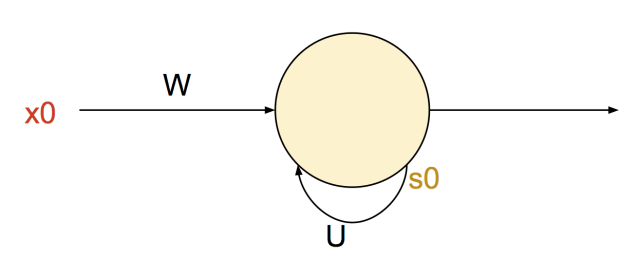
Long Short Term Memory
LSTM cells are essentially a way to make RNNs more powerful, while not having to “remember” everything (save all past states). Below, we see the basic structure of a RNN with LSTMs (shown unrolled). In essence, it is the same — it takes in data at each time step xt and produces a corresponding output yt. The unlabeled line that goes from top to bottom is the state, which is what is passed from LSTM cells from top to bottom.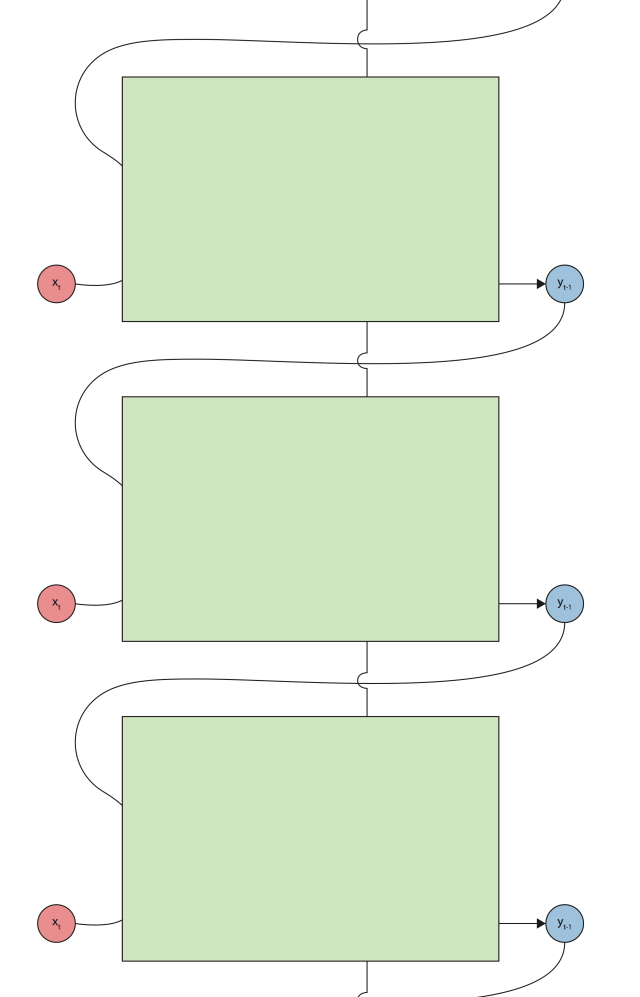 However, LSTMs are much more selective with how they remember previous state. If you turn your head to the right and only looked at the state, you’d see something like the next figure. Basically, a LSTM tries to only remember the most important parts of the state.
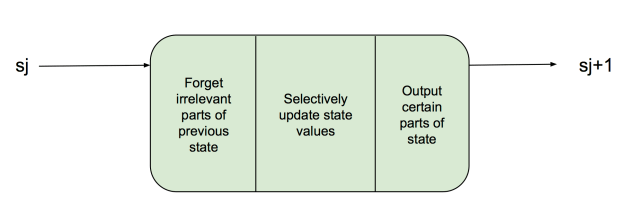
However, LSTMs are much more selective with how they remember previous state. If you turn your head to the right and only looked at the state, you’d see something like the next figure. Basically, a LSTM tries to only remember the most important parts of the state.
Zooming in further, we see that the LSTM is doing a number of things in order to only remember the most essential parts of both the state and new data. A key for this figure can be found right below.
It takes as input both the previous prediction and the new information, as well as the previous sate (shown as coming in from above now). The previous prediction and new information are separately fed into four different neural networks.
The first step is to to update the state. This is done with the output of the first three neural networks. First, data is removed from the state; then, new possibilities are generated, then filtered for only the best new bits of data, and finally combined with the state.
The next step is to make a selection for the prediction for the current time step. This is much like any other RNN, which combines a neural network with the new and previous information, combined with the previous state.
Each of these neural networks is trained using a training set, and makes up the LSTM cell.

Key:
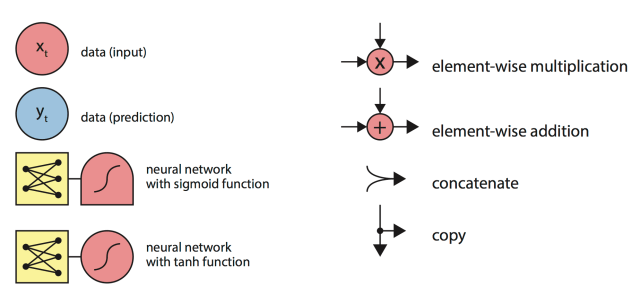
Experiments
We used Tensorflow as a deep learning framework and we trained a LSTM RNN with 512 nodes with two hidden layers. We found that varying the learning rate (e.g. backpropagation) with RMSProp to be much better for learning than a fixed rate. We also used a dictionary of words (not characters) in order to generate more readable text strings.
When training on a section of the “Lord of the Rings” books, and giving it a seed word of “Aragorn”, we got the following (somewhat ominous) text:
aragorn. ’do not open far away, that they time for the best journey from the lands of which we came with? and i knew no days, and i have never moved so, and i would now abandon me
And later got the following, more readable text:
jolly horrible! poor! ’ he hewed in the edge of eye of hand, but it’s trying to read it. there’s he not so by me: i suspect i’ll say to us, ’ said gandalf. ’are you quick?
We also trained it on the spell descriptions of the 3.5 edition of Dungeons and Dragons. It generated spell-like sentences, though of course none of them make too much sense.
spell ensures privacy for attempt a +1 enhancement bonus on damage. you concentrate.
spell allows like to animate plants, transmute your creatures.
the transmuted spell becomes smarter. the spell grants a +4 enhancement bonus to attack
( an animal spell(
Our Paper
Recurrent Neural Networks and Long Short-Term Memory Cells
Further Reading
The following resources were essential to me for getting my head wrapped around how LSTMs worked, and go into further depth than I explain in this post.
Understanding LSTMs, Christopher Olah
colah.github.io/posts/2015-08-Understanding-LSTMs/
An Introduction to LSTMs in Tensorflow, Center for Brains, Minds and Machines (CBMM)

This blog post provides an excellent overview of recurrent neural networks and their applications.
LikeLike